|
|
 发表于 2009-12-15 21:55:23
|
显示全部楼层
发表于 2009-12-15 21:55:23
|
显示全部楼层
试验1,产生最快的方波
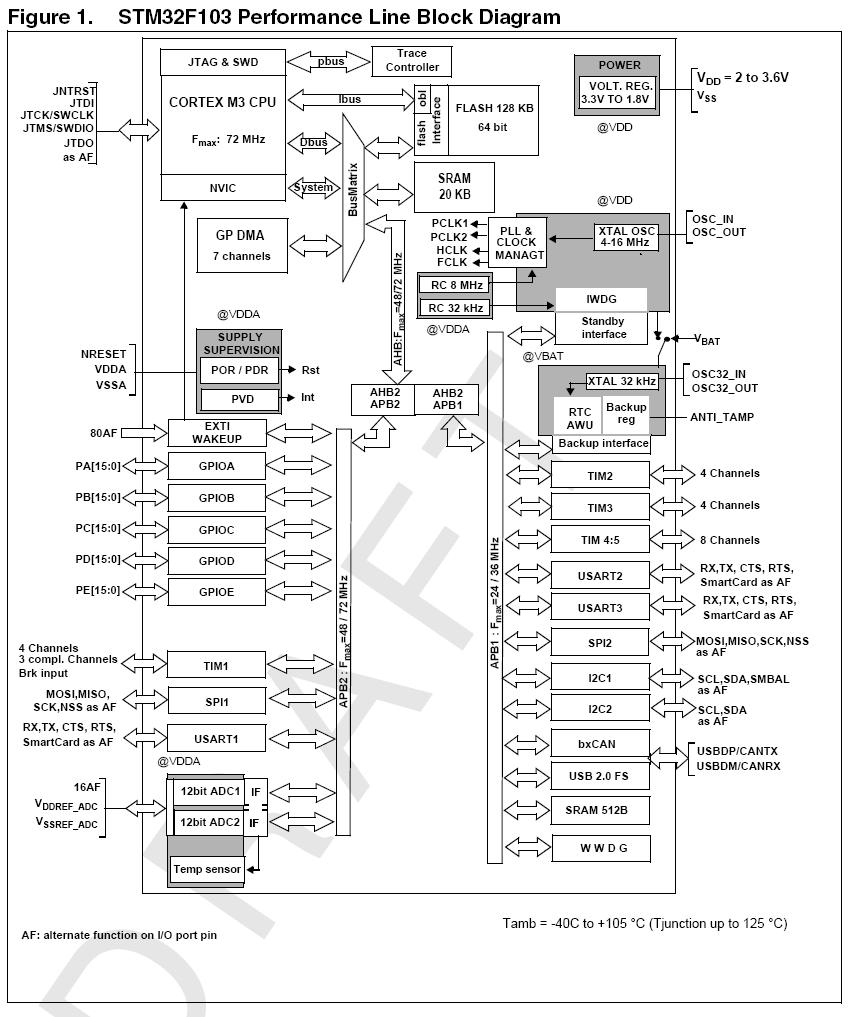
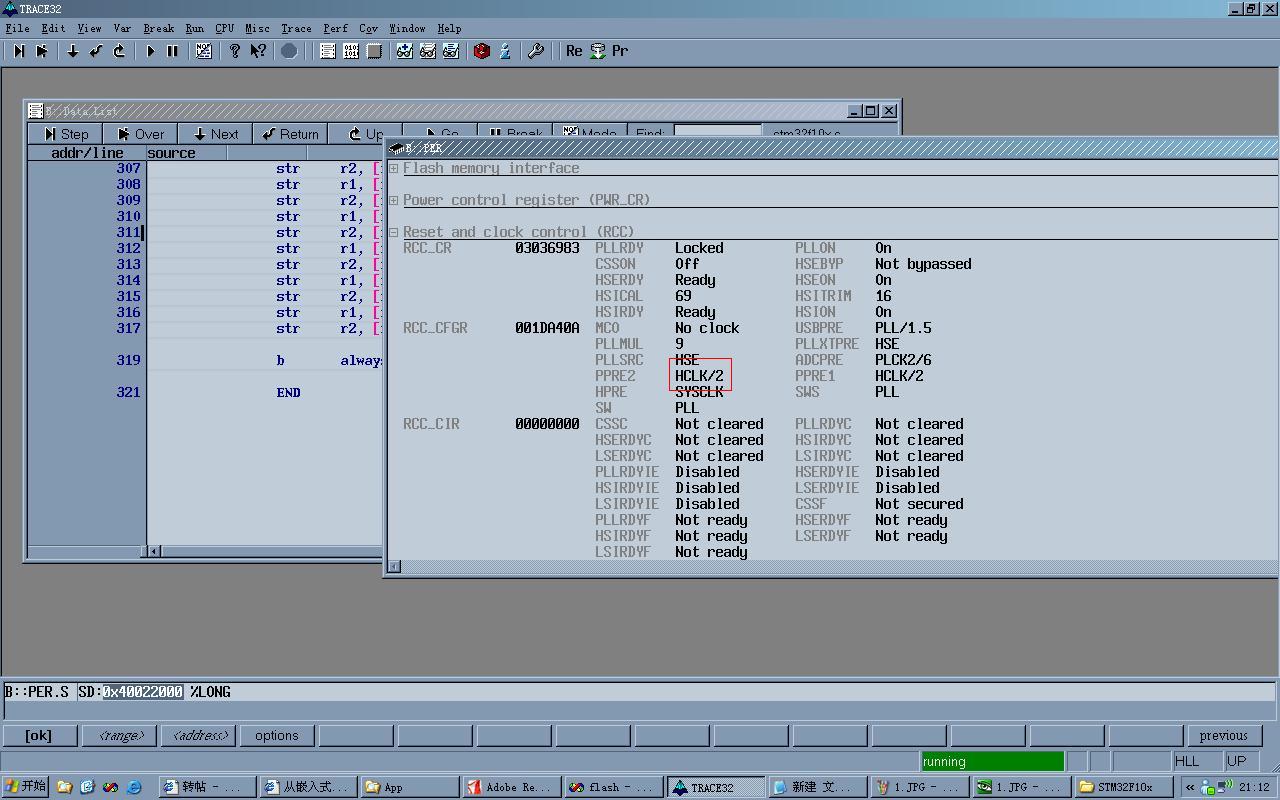
配置STM32内核频率为72Mhz(外部晶体8Mhz,倍频9),APB2总线为1分频,即72Mhz
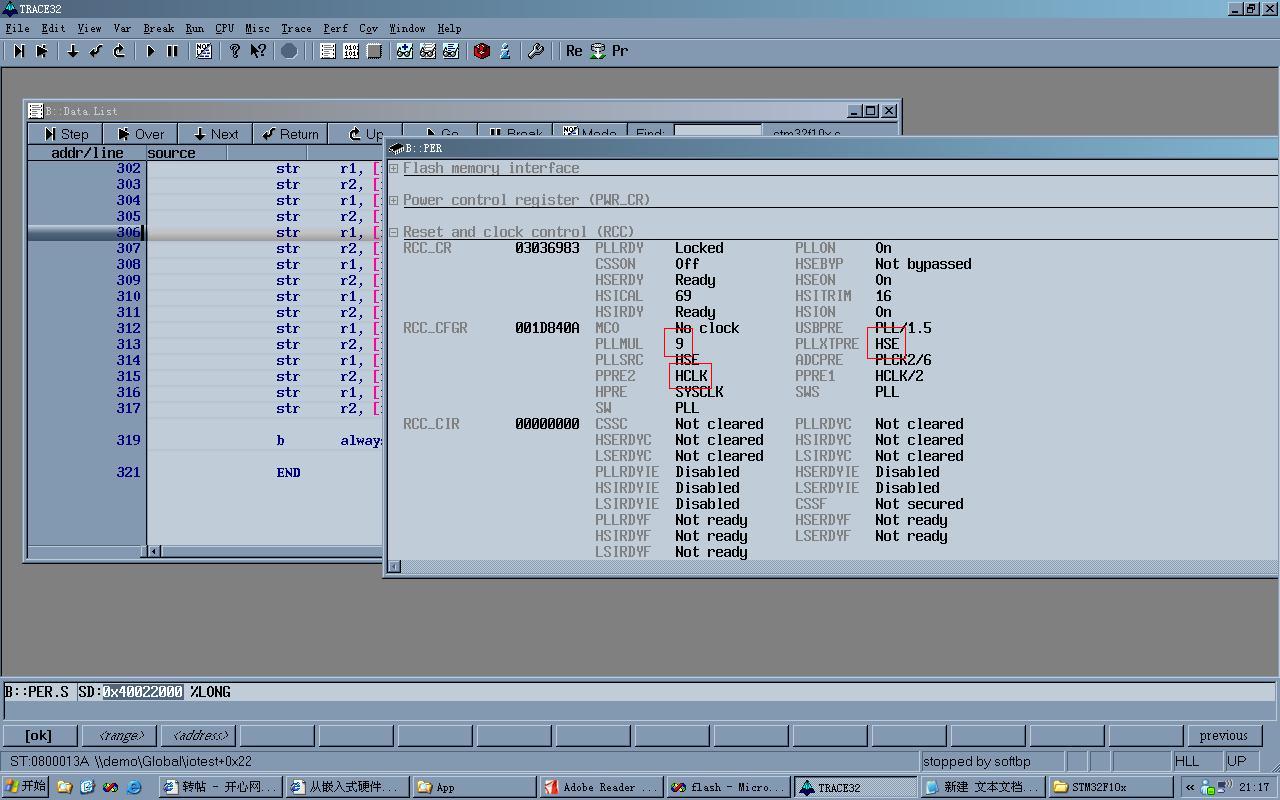
RCC参数 (原文件名:1.JPG)
部分试验代码:
EXPORT iotest
iotest
ldr r0, = 0x40010C0C
ldr r1, = 0x00000800
ldr r2, = 0
ldr r3, = 0x00000400
always_loop
str r3, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
str r1, [r0]
str r2, [r0]
b always_loop
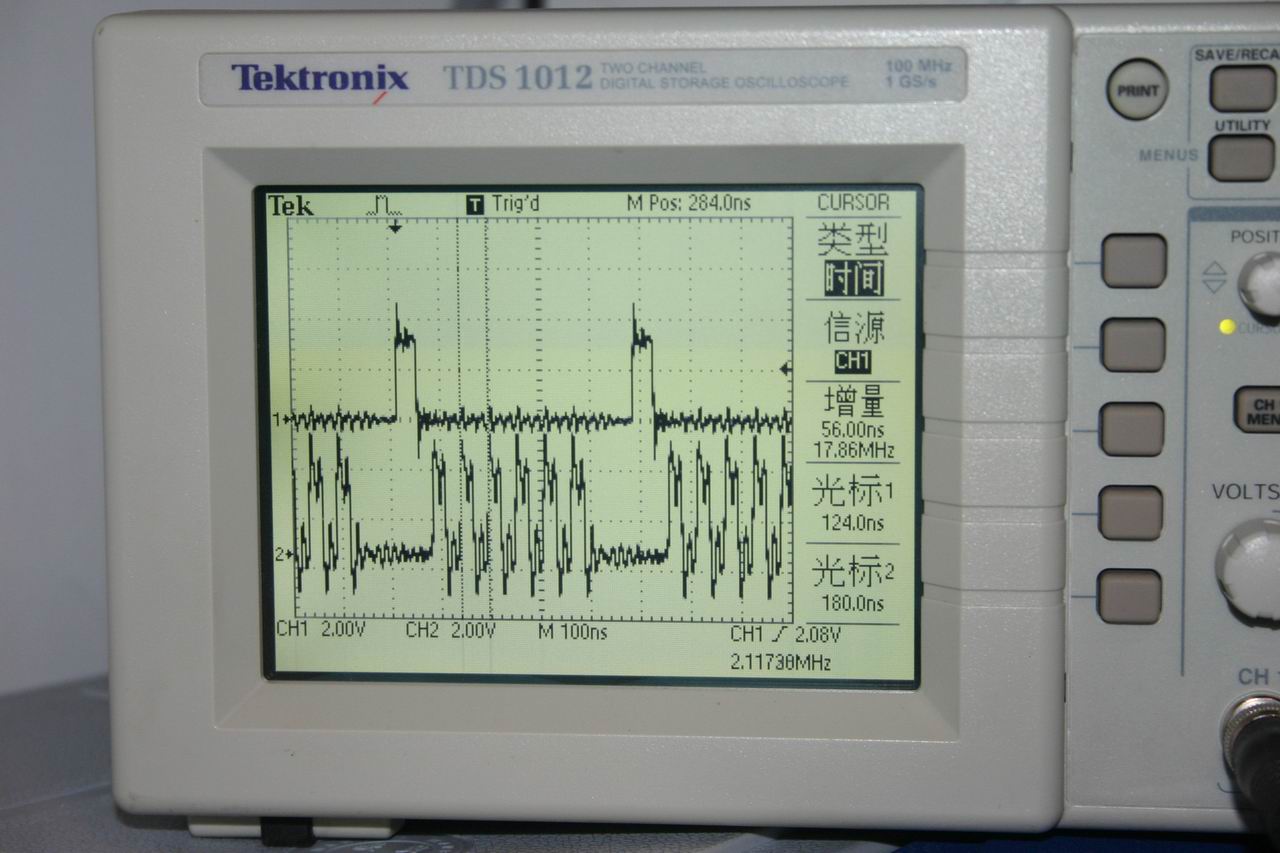
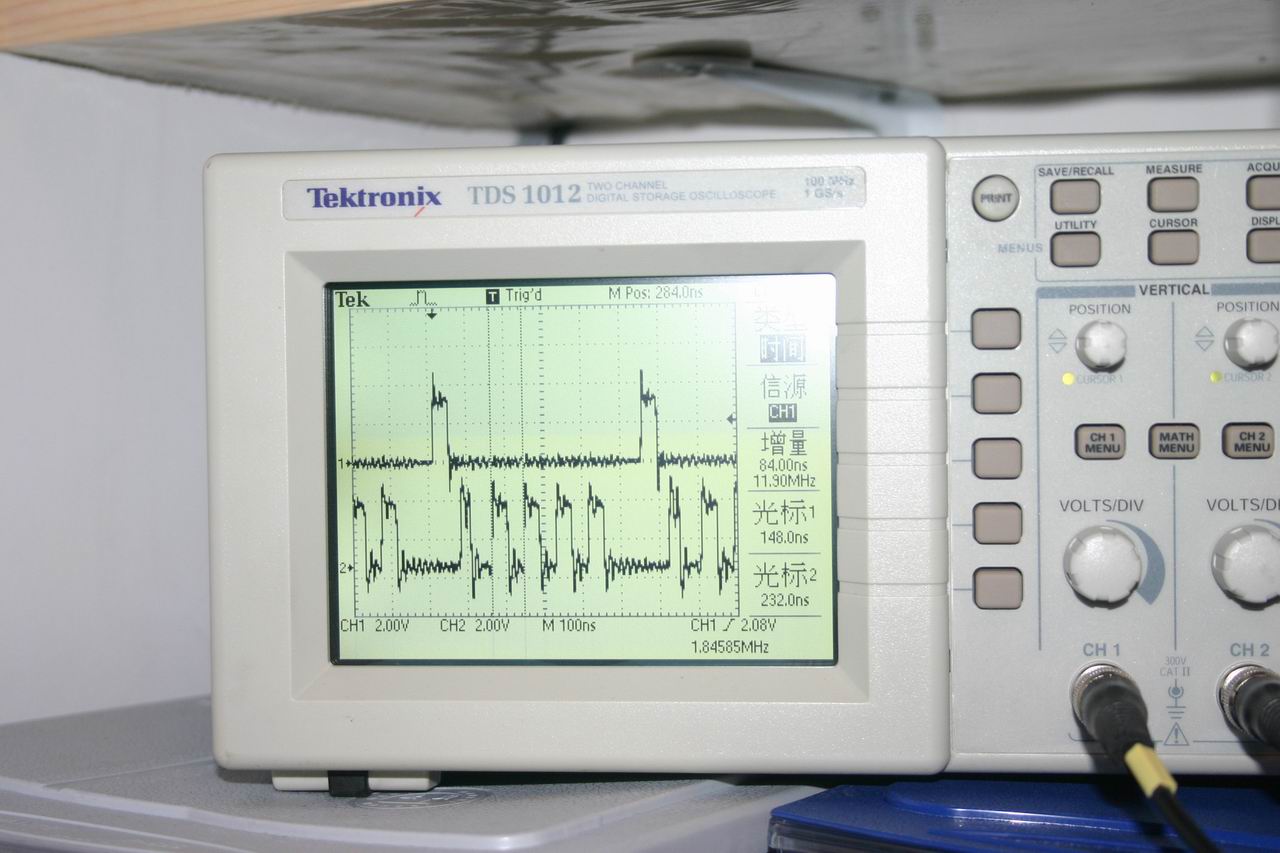
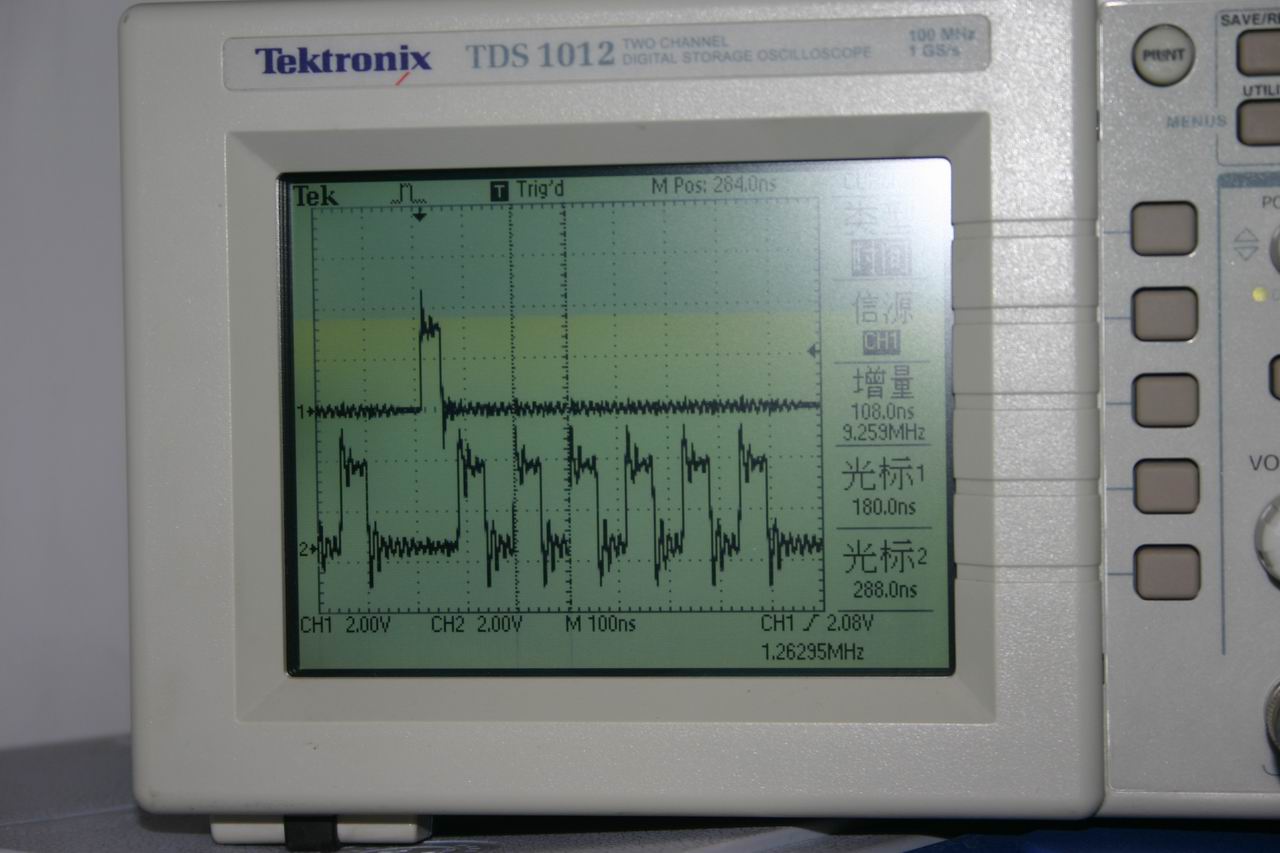
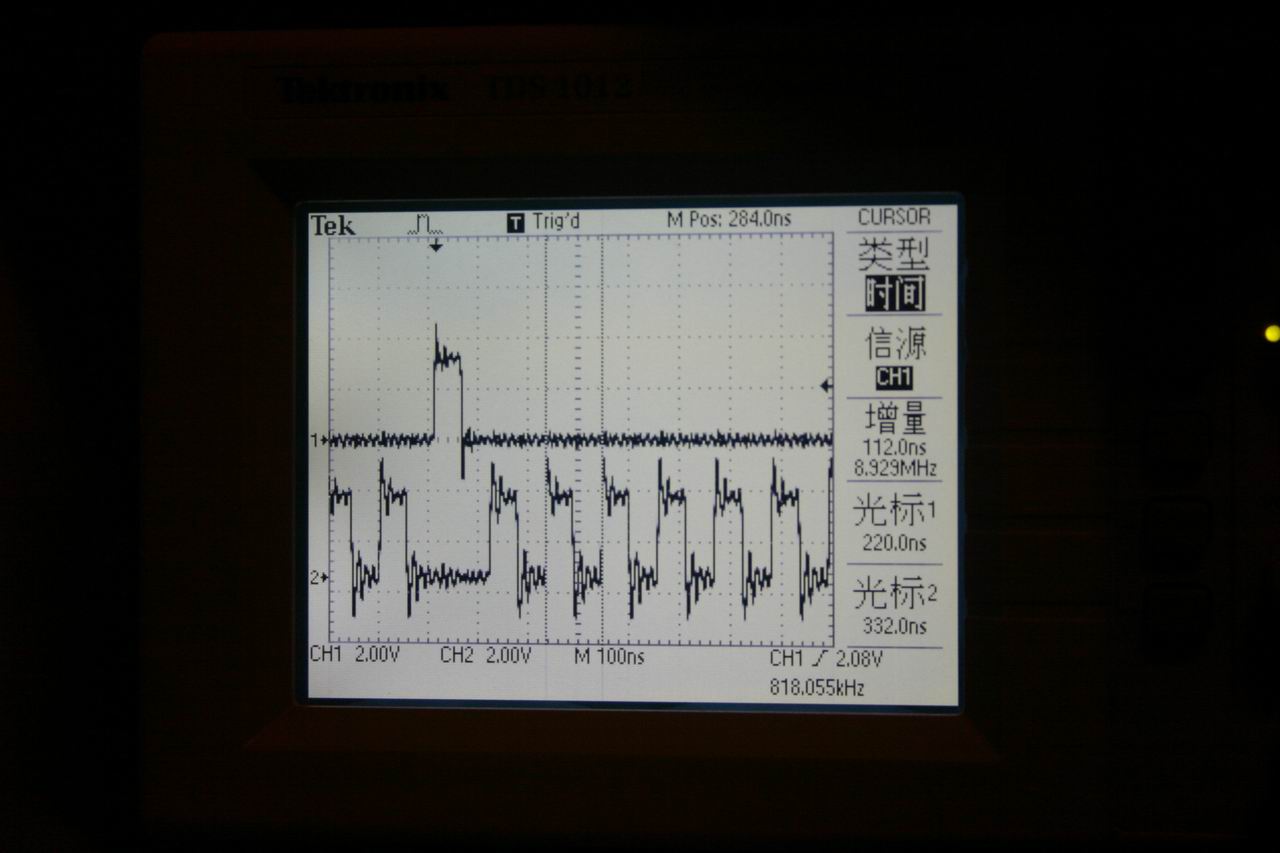
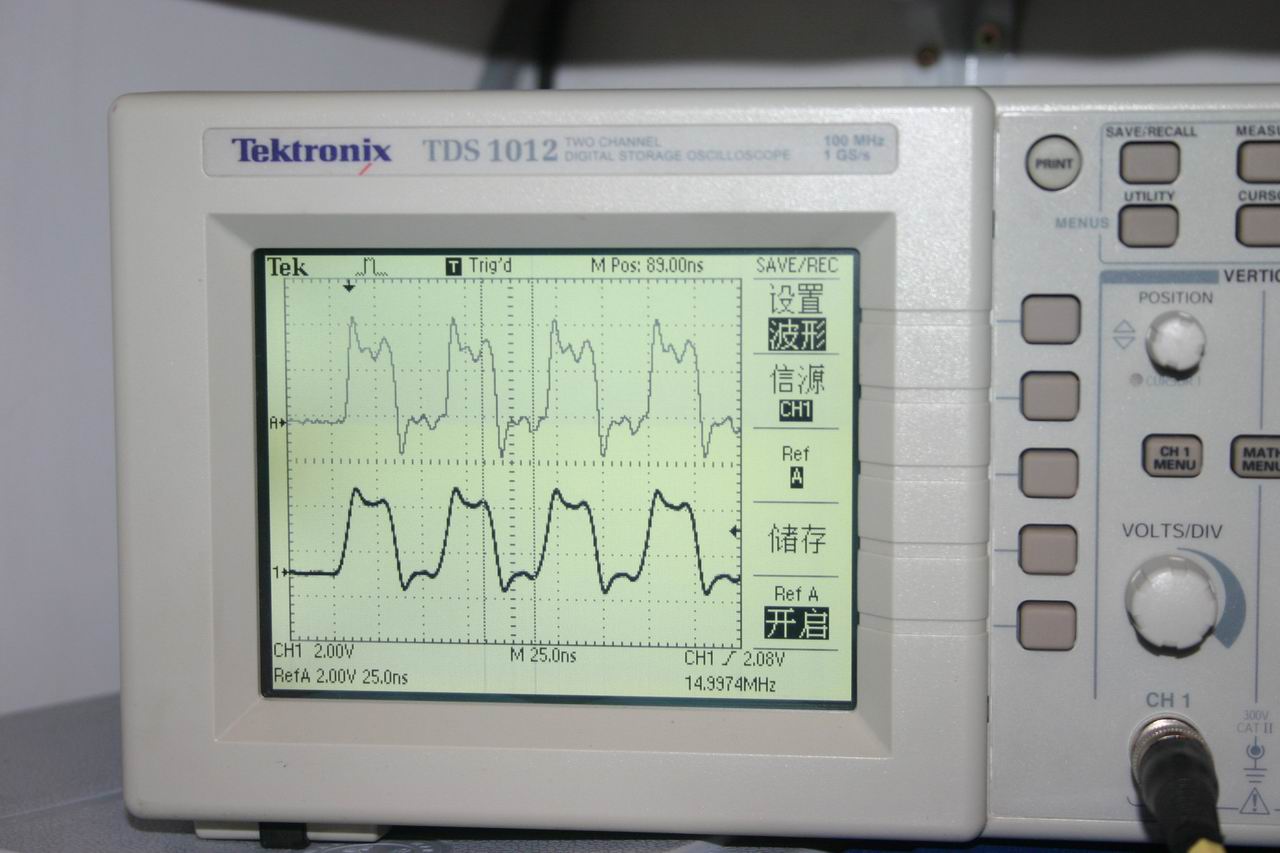
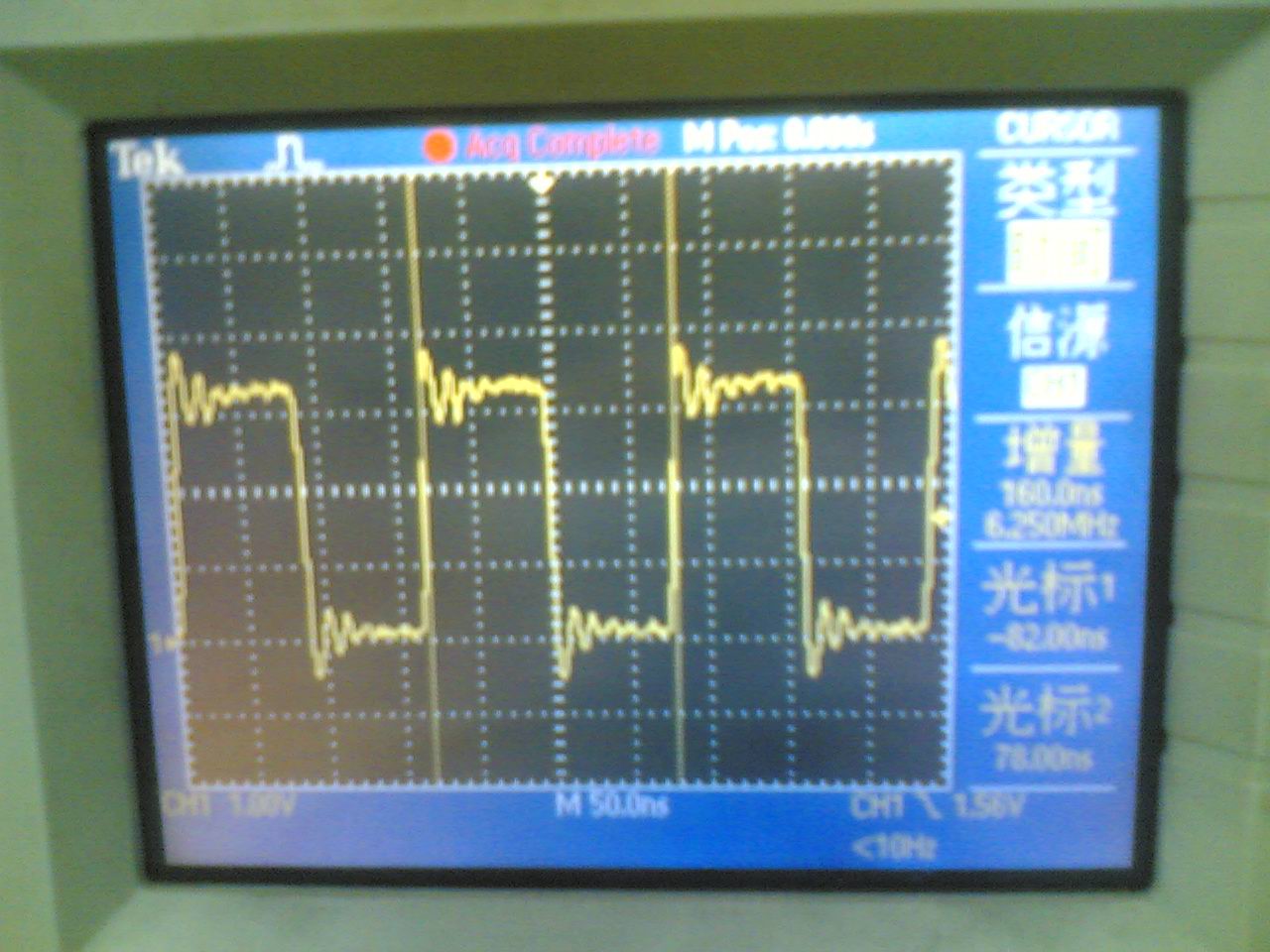
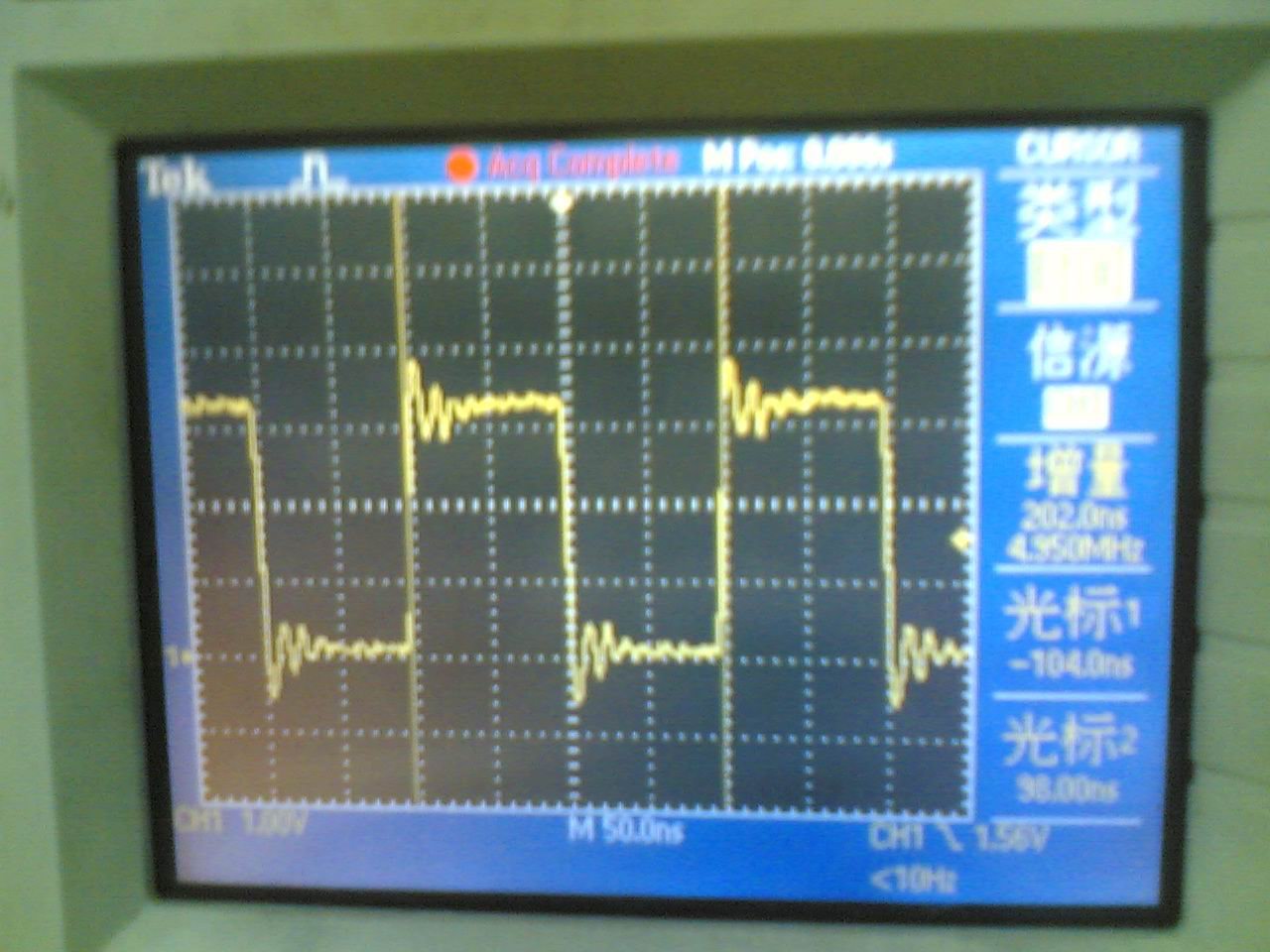
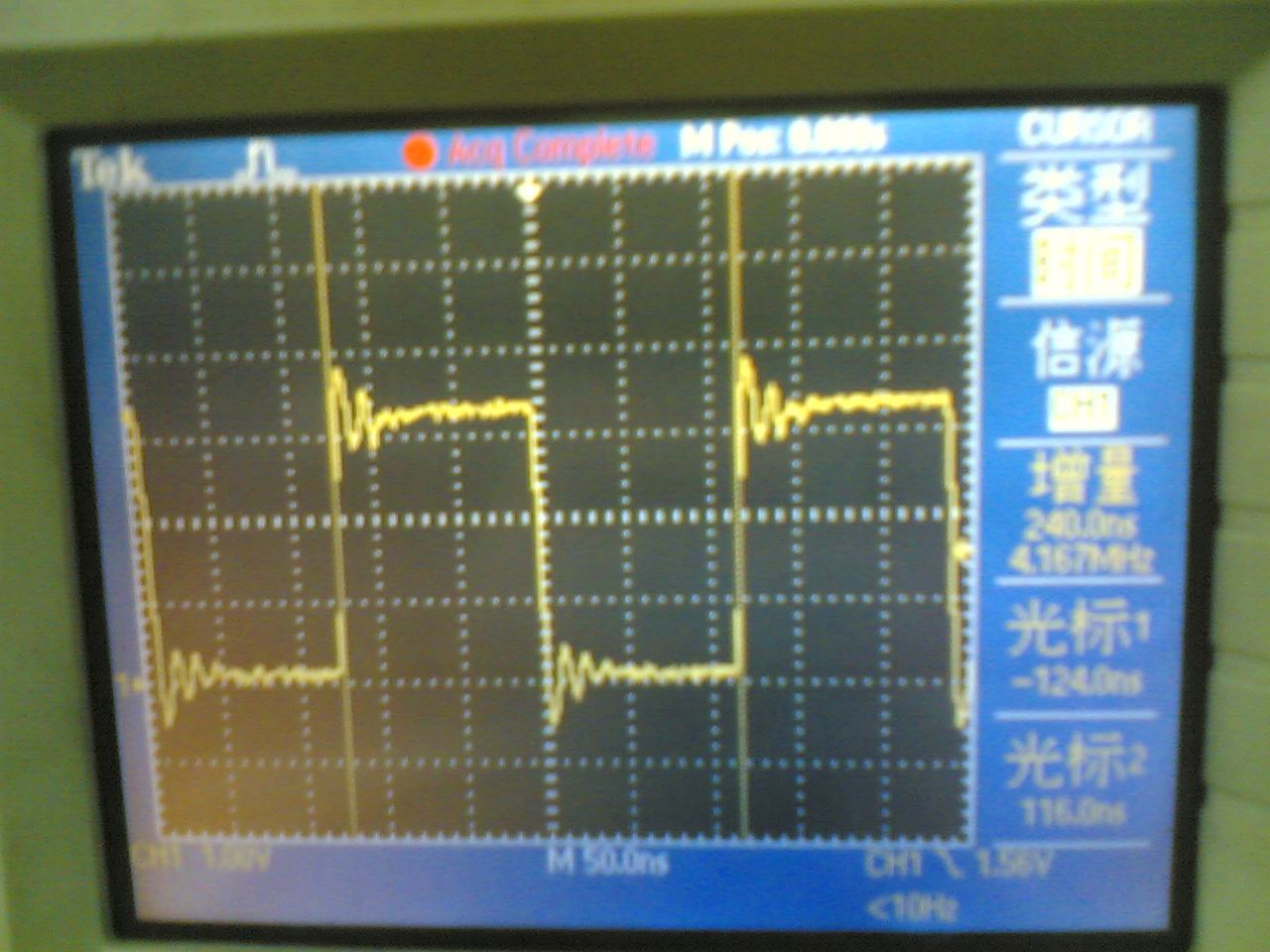
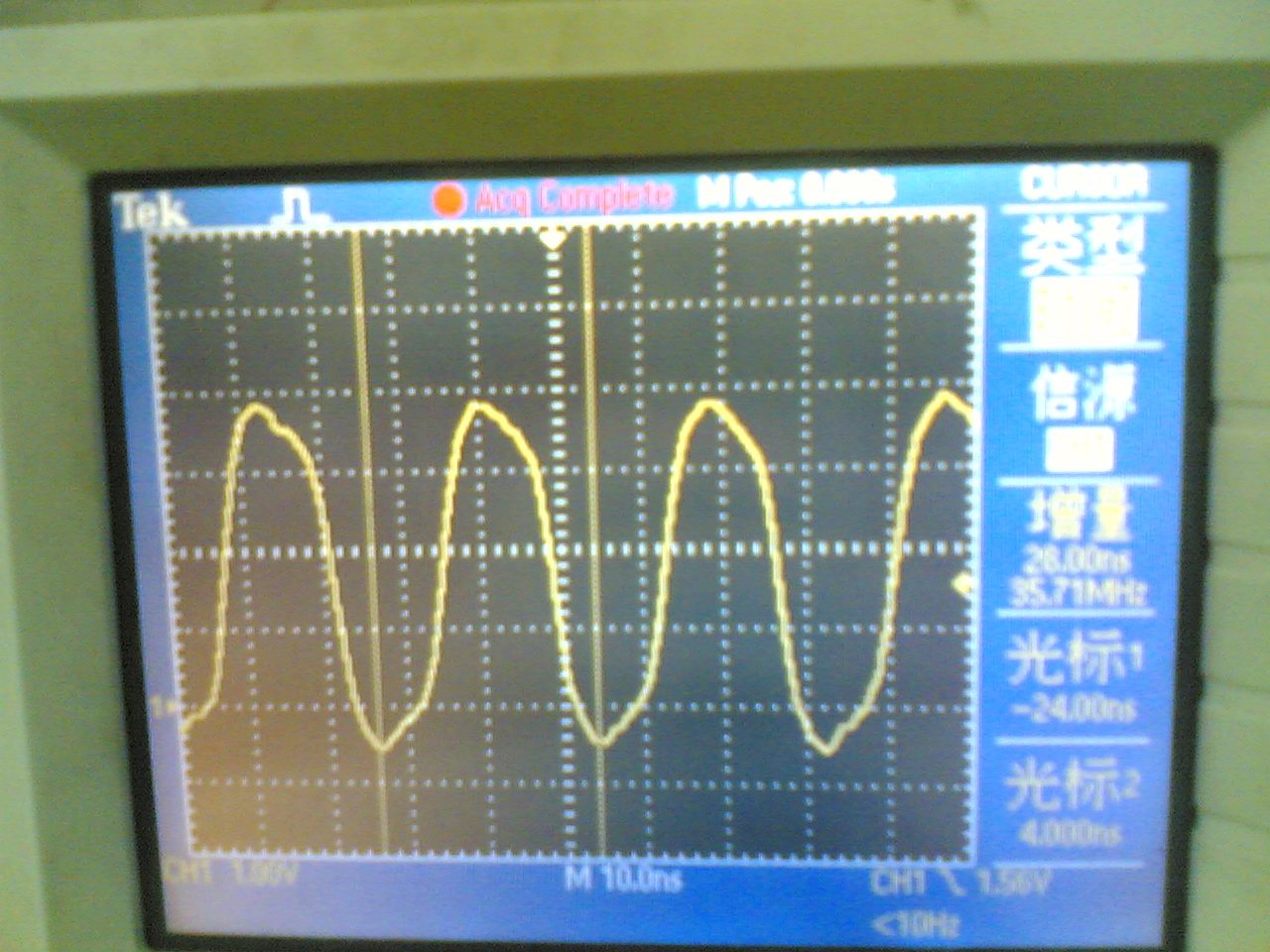
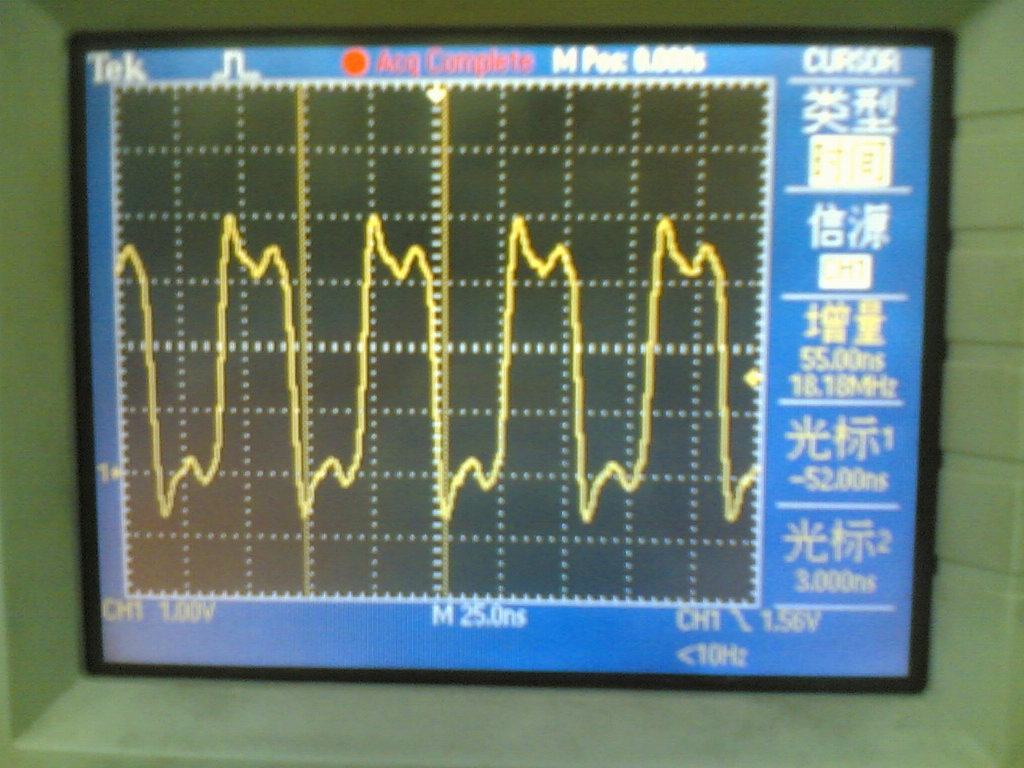
试验结果:PB11上产生约17。86Mhz方波,内核频率为72Mhz,说明此时内核每2CLK执行一次翻转IO指令
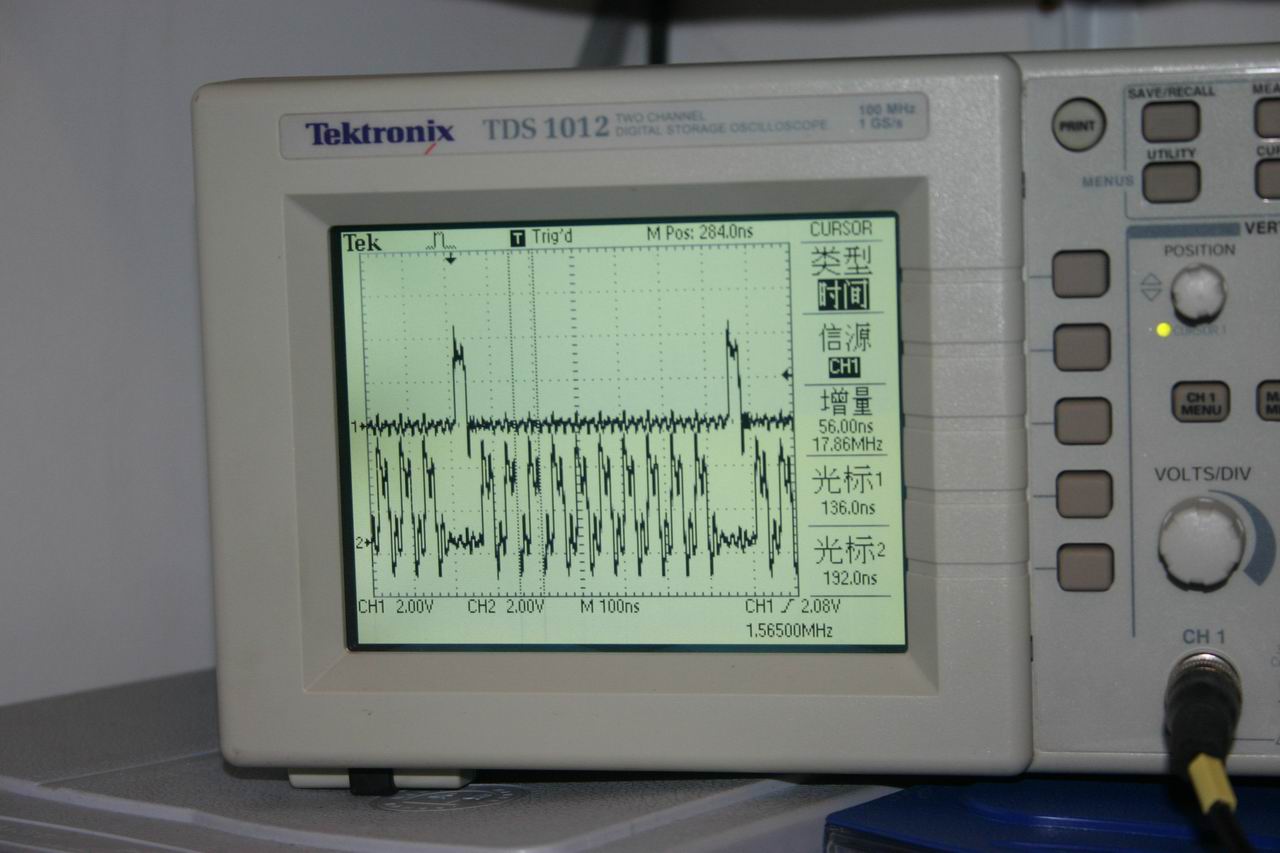
示波器测量结果 (原文件名:IMG_2265.JPG) |
|