|
|

楼主 |
发表于 2010-7-31 11:41:55
|
显示全部楼层
ram倒真是一样的。。。
cosmic的ram 有额外的x_reg,y_reg共四字节,58-4=54
iar有16字节的vreg,326-256-16=54
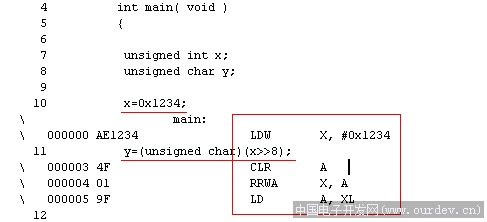
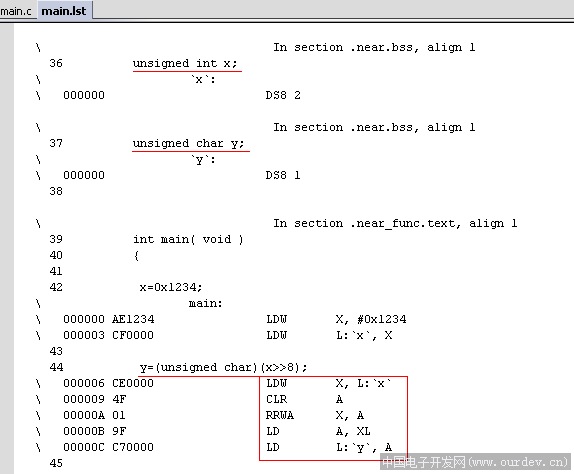
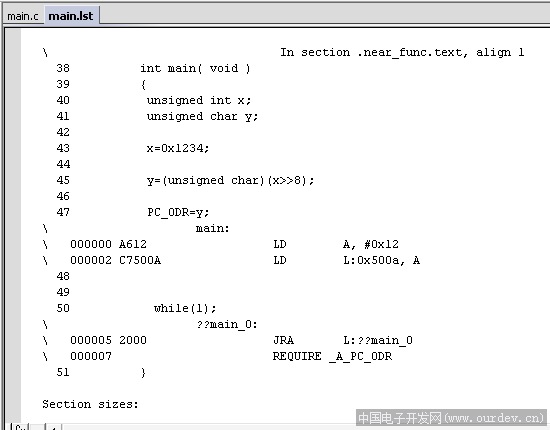
flash优化方面,我观察了下汇编。只能说目前真的不怎么样,连ST7的指令集都不会用,似乎是只使用了标准6502指令集。。。
[IAR]
8 {
9 APump.Tick = MS(500);
\ 000006 A67D LD A, #0x7d
\ 000008 C70000 LD L:APump, A
10 APump.CurLevel = LEVEL_STOP;
\ 00000B 4F CLR A
\ 00000C C70000 LD L:APump + 2, A
11 APump.IsUpdate = true;
\ 00000F A601 LD A, #0x1
\ 000011 CA0000 OR A, L:APump + 3
\ 000014 C70000 LD L:APump + 3, A
\ 000017 2000 JRA L:??APump_DoEvent_1
12 }
[cosmic]
458 0005 357d0000 mov _APump,#125
459 ; 10 APump.CurLevel = LEVEL_STOP;
460 0009 3f02 clr _APump+2
461 ; 11 APump.IsUpdate = true;
463 000b 2011 jp LC001 (后面有相同的语句,合并优化,故跳转后面去了)
...
481 001e 72100003 bset _APump+3,#0
我之前还用错了。。。IAR的代码还更大些,
有些位变量,我是用了cosmic的_Bool来定义的,在IAR中被认做了unsigned char |
|


 发表于 2010-7-30 19:01:04
发表于 2010-7-30 19:01:04