|
|
 发表于 2010-1-27 09:37:06
|
显示全部楼层
发表于 2010-1-27 09:37:06
|
显示全部楼层
个人向来不喜欢长的变量名,费劲。
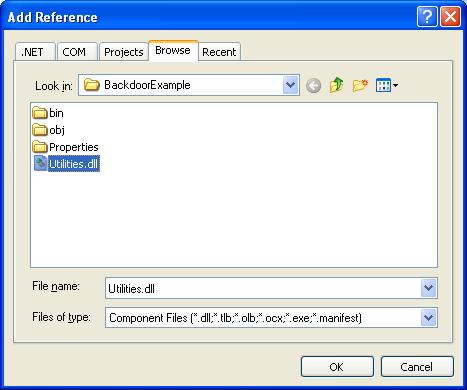
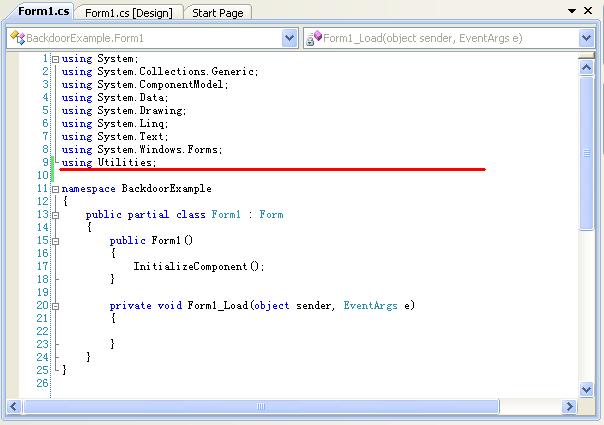
另外,针对本文所用的库Utilities.dll实在不敢恭维,明显是垃圾一堆。
对于【18楼】SkyGz
这个库是标准DLL吗,可以由其它程序如DELPHI,VB引用吗
-----------------------------------------------------------------------
所问的问题还不如自己写呢,楼主只是提供一种方法而已。不要这个库,可能更好一些吧。直接判断某个控件的KeyDown事件,也不要什么循环查询了。
附Utilities.dll反编译的一段代码,就知道该文件写的有多差劲了。要使用的人最好不要学习这种风格。
public static class Utilities.HEX.HEXBuilder
{
// Methods
public static string ByteArrayToHEXString(byte[] Datas)
{
if (Datas == null)
{
return "";
}
if (Datas.Length == 0)
{
return "";
}
StringBuilder builder = new StringBuilder();
for (int i = 0; i < Datas.Length; i++)
{
builder.Append(Datas.ToString("X2"));
builder.Append(" ");
}
return builder.ToString().Trim().ToUpper();
}
public static bool HEXStringToByteArray(string strHex, ref byte[] cResult)
{
return HEXStringToByteArray(strHex, ref cResult, true);
}
public static bool HEXStringToByteArray(string strHex, ref byte[] cResult, bool bStrictCheck)
{
uint num = 0;
uint index = 0;
bool flag = true;
if (strHex != null)
{
if (cResult == null)
{
cResult = new byte[1];
}
strHex = strHex.Trim();
strHex = strHex.ToUpper();
if (strHex.StartsWith("0X"))
{
strHex = strHex.Remove(0, 2);
}
if (cResult.Length < 1)
{
Array.Resize<byte>(ref cResult, 1);
}
cResult[0] = 0;
if (!(strHex == ""))
{
Label_0251:
if (strHex != "")
{
byte num3 = 0;
if (((num % 2) == 0) && (cResult.Length <= index))
{
Array.Resize<byte>(ref cResult, cResult.Length + 1);
}
if (strHex.StartsWith("0"))
{
flag = false;
num3 = 0;
}
else if (strHex.StartsWith("1"))
{
flag = false;
num3 = 1;
}
else if (strHex.StartsWith("2"))
{
flag = false;
num3 = 2;
}
else if (strHex.StartsWith("3"))
{
flag = false;
num3 = 3;
}
else if (strHex.StartsWith("4"))
{
flag = false;
num3 = 4;
}
else if (strHex.StartsWith("5"))
{
flag = false;
num3 = 5;
}
else if (strHex.StartsWith("6"))
{
flag = false;
num3 = 6;
}
else if (strHex.StartsWith("7"))
{
flag = false;
num3 = 7;
}
else if (strHex.StartsWith("8"))
{
flag = false;
num3 = 8;
}
else if (strHex.StartsWith("9"))
{
flag = false;
num3 = 9;
}
else if (strHex.StartsWith("A"))
{
flag = false;
num3 = 10;
}
else if (strHex.StartsWith("B"))
{
flag = false;
num3 = 11;
}
else if (strHex.StartsWith("C"))
{
flag = false;
num3 = 12;
}
else if (strHex.StartsWith("D"))
{
flag = false;
num3 = 13;
}
else if (strHex.StartsWith("E"))
{
flag = false;
num3 = 14;
}
else if (strHex.StartsWith("F"))
{
flag = false;
num3 = 15;
}
else
{
if (strHex.StartsWith(" "))
{
if (!flag)
{
flag = true;
num++;
index = num >> 1;
num = index * 2;
}
strHex = strHex.Remove(0, 1);
goto Label_0251;
}
return (!bStrictCheck && (num > 0));
}
cResult[index] = (byte) (cResult[index] << 4);
cResult[index] = (byte) (cResult[index] | num3);
num++;
index = num >> 1;
strHex = strHex.Remove(0, 1);
goto Label_0251;
}
return true;
}
}
return false;
}
public static bool HEXStringToU16Array(string strHex, ref ushort[] hwResult)
{
return HEXStringToU16Array(strHex, ref hwResult, true);
}
public static bool HEXStringToU16Array(string strHex, ref ushort[] hwResult, bool bStrictCheck)
{
uint num = 0;
if (strHex != null)
{
if (hwResult == null)
{
hwResult = new ushort[1];
}
strHex = strHex.Trim();
strHex = strHex.ToUpper();
if (strHex.StartsWith("0X"))
{
strHex = strHex.Remove(0, 2);
}
if (hwResult.Length < 1)
{
Array.Resize<ushort>(ref hwResult, 1);
}
hwResult[0] = 0;
if (!(strHex == ""))
{
while (strHex != "")
{
if (((num % 4) == 0) && (hwResult.Length <= (num >> 2)))
{
Array.Resize<ushort>(ref hwResult, hwResult.Length + 1);
}
byte num2 = 0;
if (strHex.StartsWith("0"))
{
num2 = 0;
}
else if (strHex.StartsWith("1"))
{
num2 = 1;
}
else if (strHex.StartsWith("2"))
{
num2 = 2;
}
else if (strHex.StartsWith("3"))
{
num2 = 3;
}
else if (strHex.StartsWith("4"))
{
num2 = 4;
}
else if (strHex.StartsWith("5"))
{
num2 = 5;
}
else if (strHex.StartsWith("6"))
{
num2 = 6;
}
else if (strHex.StartsWith("7"))
{
num2 = 7;
}
else if (strHex.StartsWith("8"))
{
num2 = 8;
}
else if (strHex.StartsWith("9"))
{
num2 = 9;
}
else if (strHex.StartsWith("A"))
{
num2 = 10;
}
else if (strHex.StartsWith("B"))
{
num2 = 11;
}
else if (strHex.StartsWith("C"))
{
num2 = 12;
}
else if (strHex.StartsWith("D"))
{
num2 = 13;
}
else if (strHex.StartsWith("E"))
{
num2 = 14;
}
else if (strHex.StartsWith("F"))
{
num2 = 15;
}
else
{
return (!bStrictCheck && (num > 0));
}
hwResult[num >> 2] = (ushort) (hwResult[num >> 2] << 4);
hwResult[num >> 2] = (ushort) (hwResult[num >> 2] | num2);
num++;
strHex = strHex.Remove(0, 1);
}
return true;
}
}
return false;
}
public static bool HEXStringToU32Array(string strHex, ref uint[] hwResult)
{
return HEXStringToU32Array(strHex, ref hwResult, true);
}
public static bool HEXStringToU32Array(string strHex, ref uint[] wResult, bool bStrictCheck)
{
uint num = 0;
if (strHex != null)
{
if (wResult == null)
{
wResult = new uint[1];
}
strHex = strHex.Trim();
strHex = strHex.ToUpper();
if (strHex.StartsWith("0X"))
{
strHex = strHex.Remove(0, 2);
}
if (wResult.Length < 1)
{
Array.Resize<uint>(ref wResult, 1);
}
wResult[0] = 0;
if (!(strHex == ""))
{
while (strHex != "")
{
if (((num % 8) == 0) && (wResult.Length <= (num >> 3)))
{
Array.Resize<uint>(ref wResult, wResult.Length + 1);
}
byte num2 = 0;
if (strHex.StartsWith("0"))
{
num2 = 0;
}
else if (strHex.StartsWith("1"))
{
num2 = 1;
}
else if (strHex.StartsWith("2"))
{
num2 = 2;
}
else if (strHex.StartsWith("3"))
{
num2 = 3;
}
else if (strHex.StartsWith("4"))
{
num2 = 4;
}
else if (strHex.StartsWith("5"))
{
num2 = 5;
}
else if (strHex.StartsWith("6"))
{
num2 = 6;
}
else if (strHex.StartsWith("7"))
{
num2 = 7;
}
else if (strHex.StartsWith("8"))
{
num2 = 8;
}
else if (strHex.StartsWith("9"))
{
num2 = 9;
}
else if (strHex.StartsWith("A"))
{
num2 = 10;
}
else if (strHex.StartsWith("B"))
{
num2 = 11;
}
else if (strHex.StartsWith("C"))
{
num2 = 12;
}
else if (strHex.StartsWith("D"))
{
num2 = 13;
}
else if (strHex.StartsWith("E"))
{
num2 = 14;
}
else if (strHex.StartsWith("F"))
{
num2 = 15;
}
else
{
return (!bStrictCheck && (num > 0));
}
wResult[num >> 3] = wResult[num >> 3] << 4;
wResult[num >> 3] |= num2;
num++;
strHex = strHex.Remove(0, 1);
}
return true;
}
}
return false;
}
public static bool HEXStringToU64Array(string strHex, ref ulong[] hwResult)
{
return HEXStringToU64Array(strHex, ref hwResult, true);
}
public static bool HEXStringToU64Array(string strHex, ref ulong[] dwResult, bool bStrictCheck)
{
uint num = 0;
if (strHex != null)
{
if (dwResult == null)
{
dwResult = new ulong[1];
}
strHex = strHex.Trim();
strHex = strHex.ToUpper();
if (strHex.StartsWith("0X"))
{
strHex = strHex.Remove(0, 2);
}
if (dwResult.Length < 1)
{
Array.Resize<ulong>(ref dwResult, 1);
}
dwResult[0] = 0L;
if (!(strHex == ""))
{
while (strHex != "")
{
if (((num % 0x10) == 0) && (dwResult.Length <= (num >> 4)))
{
Array.Resize<ulong>(ref dwResult, dwResult.Length + 1);
}
byte num2 = 0;
if (strHex.StartsWith("0"))
{
num2 = 0;
}
else if (strHex.StartsWith("1"))
{
num2 = 1;
}
else if (strHex.StartsWith("2"))
{
num2 = 2;
}
else if (strHex.StartsWith("3"))
{
num2 = 3;
}
else if (strHex.StartsWith("4"))
{
num2 = 4;
}
else if (strHex.StartsWith("5"))
{
num2 = 5;
}
else if (strHex.StartsWith("6"))
{
num2 = 6;
}
else if (strHex.StartsWith("7"))
{
num2 = 7;
}
else if (strHex.StartsWith("8"))
{
num2 = 8;
}
else if (strHex.StartsWith("9"))
{
num2 = 9;
}
else if (strHex.StartsWith("A"))
{
num2 = 10;
}
else if (strHex.StartsWith("B"))
{
num2 = 11;
}
else if (strHex.StartsWith("C"))
{
num2 = 12;
}
else if (strHex.StartsWith("D"))
{
num2 = 13;
}
else if (strHex.StartsWith("E"))
{
num2 = 14;
}
else if (strHex.StartsWith("F"))
{
num2 = 15;
}
else
{
return (!bStrictCheck && (num > 0));
}
dwResult[num >> 4] = dwResult[num >> 4] << 4;
dwResult[num >> 4] |= num2;
num++;
strHex = strHex.Remove(0, 1);
}
return true;
}
}
return false;
}
}
真服了,十六进制的字符转成十进制数字有那么复杂么?C#我不太懂,Delphi中StrToInt就搞定了,C中atoi也可以,不调用库函数直接减去'0'或('A'+10)也并不麻烦。 |
|



 楼主
楼主